- How it works: Uses another language model (the “judge”) to score or critique the output of your target prompt based on specific criteria (e.g., helpfulness, clarity, adherence to instructions).
- Best for: Subjective criteria, complex assessments, evaluating nuanced qualities like creativity or tone.
Setup
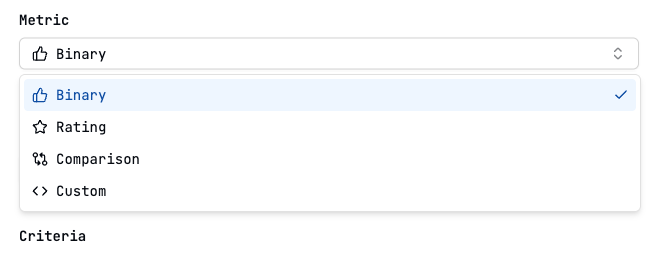
Metrics
Binary
Judges whether the response meets the criteria. The resulting score is
“passed” or “failed”
Rating
Judges the response by rating it under a criteria. The resulting score is the
rating
Comparison
Judges the response by comparing the criteria to the expected output. The
resulting score is the percentage of compared criteria that is met
Custom
Judges the response under a criteria using a custom prompt. The resulting
score is the value of criteria that is met
Expected output
The expected output, also known as label, refers to the correct or ideal response that the language model should generate for a given prompt. You can create datasets with expected output columns to evaluate prompts with ground truth.Comparison and Custom (labeled) metrics require an expected output.
Templates
We have a list of pre-configured LLM-as-a-judge templates that you can use to quickly set up evaluations. These templates cover common evaluation scenarios and can be customized to fit your specific needs.- Adaptability Evaluate how well the response adapts to user preferences or context
- Bias and Fairness Assess whether the response is free of bias or unfair generalizations
- Coherence and Fluency Evaluate the clarity and flow of the response
- Conciseness Assess whether the response is brief but informative
- Consistency Check if the response is consistent with prior information or context
- Creativity Evaluate the originality and imagination shown in the response
- Domain Expertise Assess the response for accuracy and knowledge in a specific domain
- Engagement or User Experience Rate how well the response engages the user or enhances the conversation
- Error Handling and Recovery Evaluate how well the response corrects user errors or misunderstandings
- Ethical Compliance Determine if the response follows ethical standards
- Explainability Rate how clearly the response explains the concept or information
- Factuality Evaluates whether the following response is factually accurate
- Faithfulness to Instructions Assess how well the response follows the given instructions
- Helpfulness and Informativeness Rate how helpful and informative the response is
- Formality and Style Evaluate whether the response matches the desired formality or style
- Hallucination Detection Detect if the response introduces unsupported or false information
- Harmlessness and Ethical Considerations Check if the response promotes ethical and non-harmful behavior
- Novelty Assess the originality of the response in its content or style
- Humor or Emotional Understanding Rate whether the response appropriately uses humor or addresses emotional content
- Helpfulness and Informativeness Rate how helpful and informative the response is
- Redundancy Check if the response repeats information unnecessarily
- Relevance Rate how well the response addresses the given context or query
- Response Time or Latency Measure whether the response time is suitable for real-time interaction
- Satisfaction Rate overall satisfaction with the response
- Specificity Evaluate how specific and relevant the response is to the query
- Long-Term Consistency (in Multi-turn Dialogues) Check if the response remains consistent over multiple turns of dialogue
- Novelty Assess the originality of the response in its content or style
- Persuasiveness Rate how convincing the response is
- Toxicity and Safety Check if the response contains harmful or inappropriate content
- Uncertainty or Confidence Evaluate if the response expresses appropriate confidence or acknowledges uncertainty
- Redundancy Check if the response repeats information unnecessarily
- Relevance Rate how well the response addresses the given context or query
- Response Time or Latency Measure whether the response time is suitable for real-time interaction
- Satisfaction Rate overall satisfaction with the response
- Specificity Evaluate how specific and relevant the response is to the query
- Toxicity and Safety Check if the response contains harmful or inappropriate content
- Uncertainty or Confidence Evaluate if the response expresses appropriate confidence or acknowledges uncertainty