- How it works: Team members manually review prompt outputs (logs) and assign scores or labels based on their judgment.
- Best for: Capturing nuanced human preferences, evaluating criteria difficult for LLMs to judge, initial quality assessment, creating golden datasets for other evaluation types.
- Requires: Setting up manual review workflows and criteria for reviewers.
Because HITL evaluations require manual input, they do not support automatic
live or batch execution like LLM-as-Judge or Programmatic Rules. Feedback
must be submitted individually for each log reviewed.
Setup
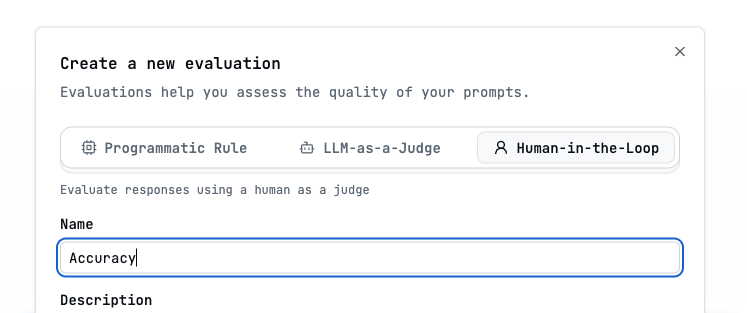
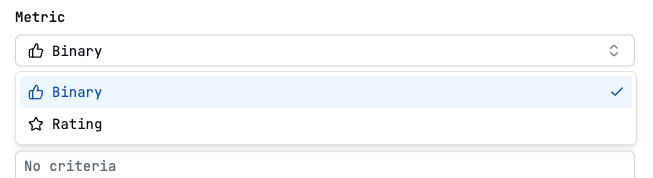
Metrics
Binary
Judges whether the response meets the criteria. The resulting score is
“passed” or “failed”
Rating
Judges the response by rating it under a criteria. The resulting score is the
rating
Annotate logs in Latitude UI
Manually submitted results appear alongside other evaluation results:- Logs View: Attached to the individual log entry.
- Evaluations Tab: Aggregated statistics and distributions for the HITL evaluation.