Running Evaluations on Datasets (Batch Mode)
Batch evaluations allow you to assess prompt performance across a predefined set of inputs and expected outputs contained within a Dataset. Use Cases:- Testing prompt changes against a golden dataset (regression testing).
- Comparing different prompt versions (A/B testing) on the same inputs.
- Evaluating performance on specific edge cases or scenarios defined in the dataset.
- Generating scores for metrics that require ground truth (e.g., Exact Match, Semantic Similarity).
-
Ensure you have a Dataset prepared with relevant inputs (and
expected_outputcolumns if needed by your evaluation metrics). - Navigate to the specific Evaluation you want to run (within your prompt’s “Evaluations” tab).
-
Click the “Run experiment” button.
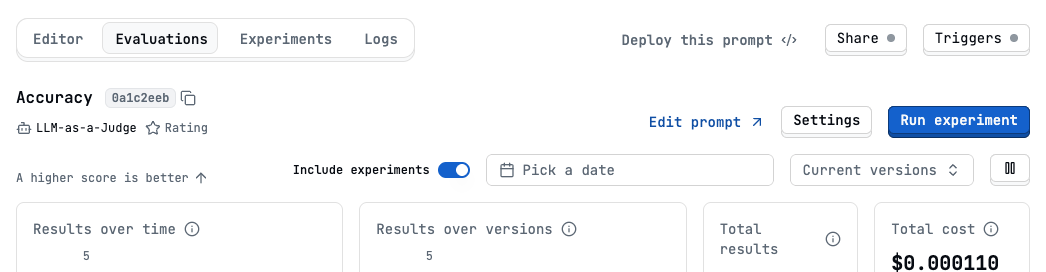
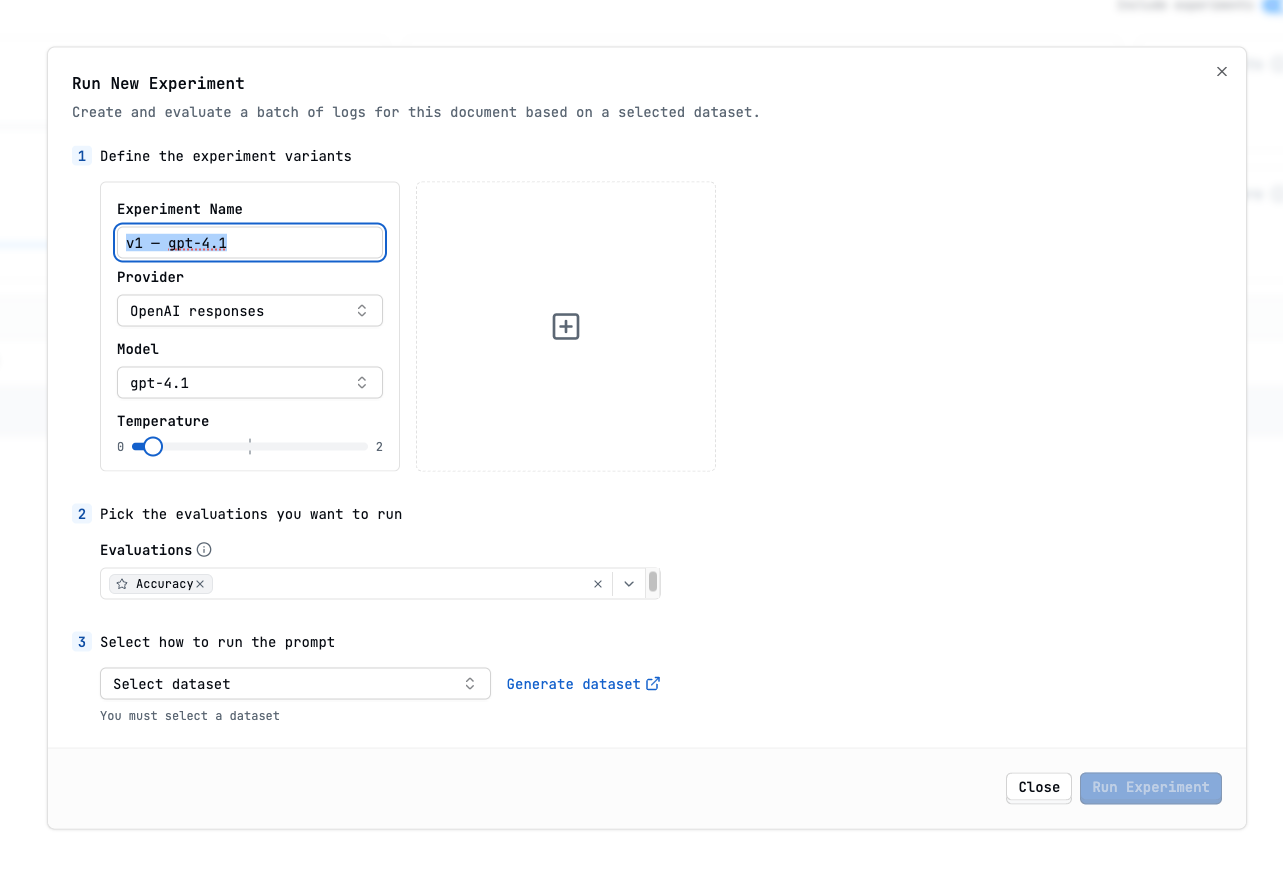
- Define the experiment variants
-
Select the Dataset you want to run the experiment against.
-
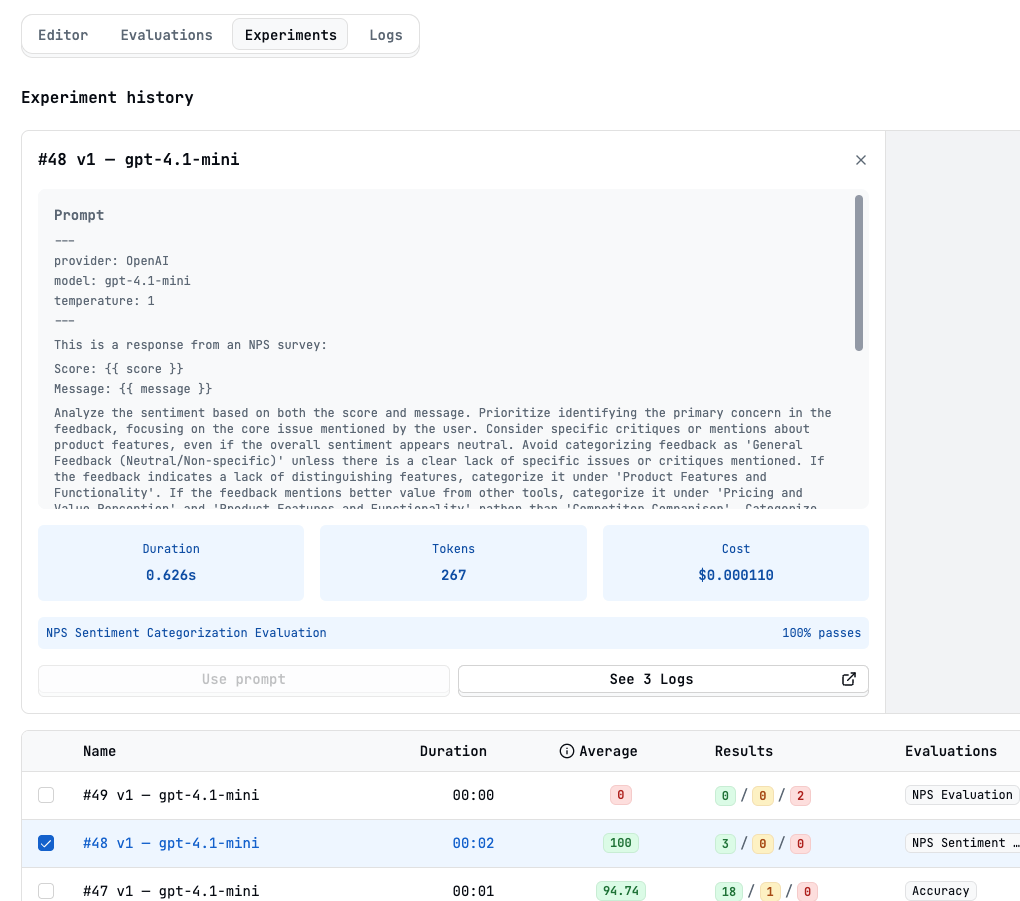
You will be redirected to the experiments tab with the results
Running Evaluations Continuously (Live Mode)
Live evaluations automatically run on new logs as they are generated by your prompt in production (via API calls or the Playground). This provides continuous monitoring of prompt quality.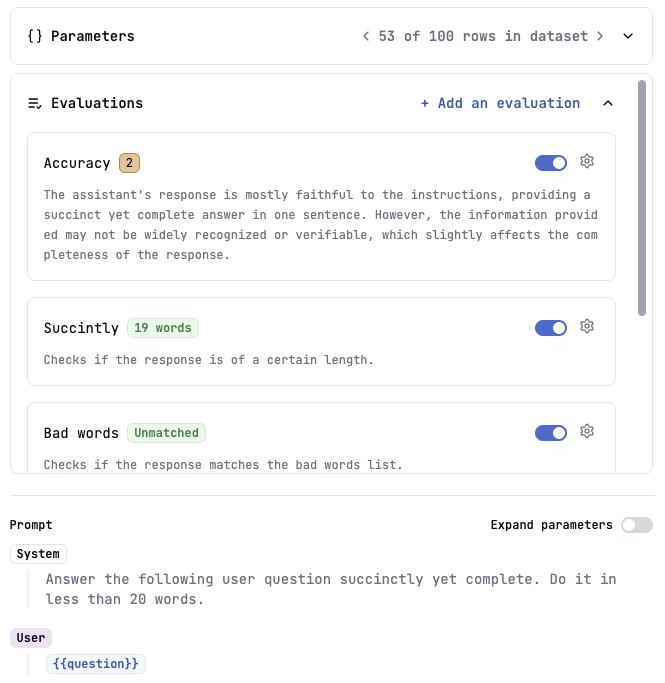
- Real-time monitoring of key quality metrics (e.g., validity, safety, basic helpfulness).
- Quickly detecting performance regressions caused by model updates or unexpected inputs.
- Tracking overall prompt performance trends over time.
- Navigate to the specific Evaluation you want to run live.
- Go to its settings.
- Toggle the “Live Evaluation” option ON.
- Save the settings.
Evaluations requiring an
expected_output (like Exact Match, Lexical Overlap,
Semantic or Numeric Similarity…), Manual
Evaluations or Composite
Evaluations cannot run in live
mode, as they might need pre-existing ground truth or human input.Viewing Evaluation Results
Whether run experiments or live mode, results are accessible:- Logs View: Individual logs show scores/results from all applicable evaluations that have run on them.
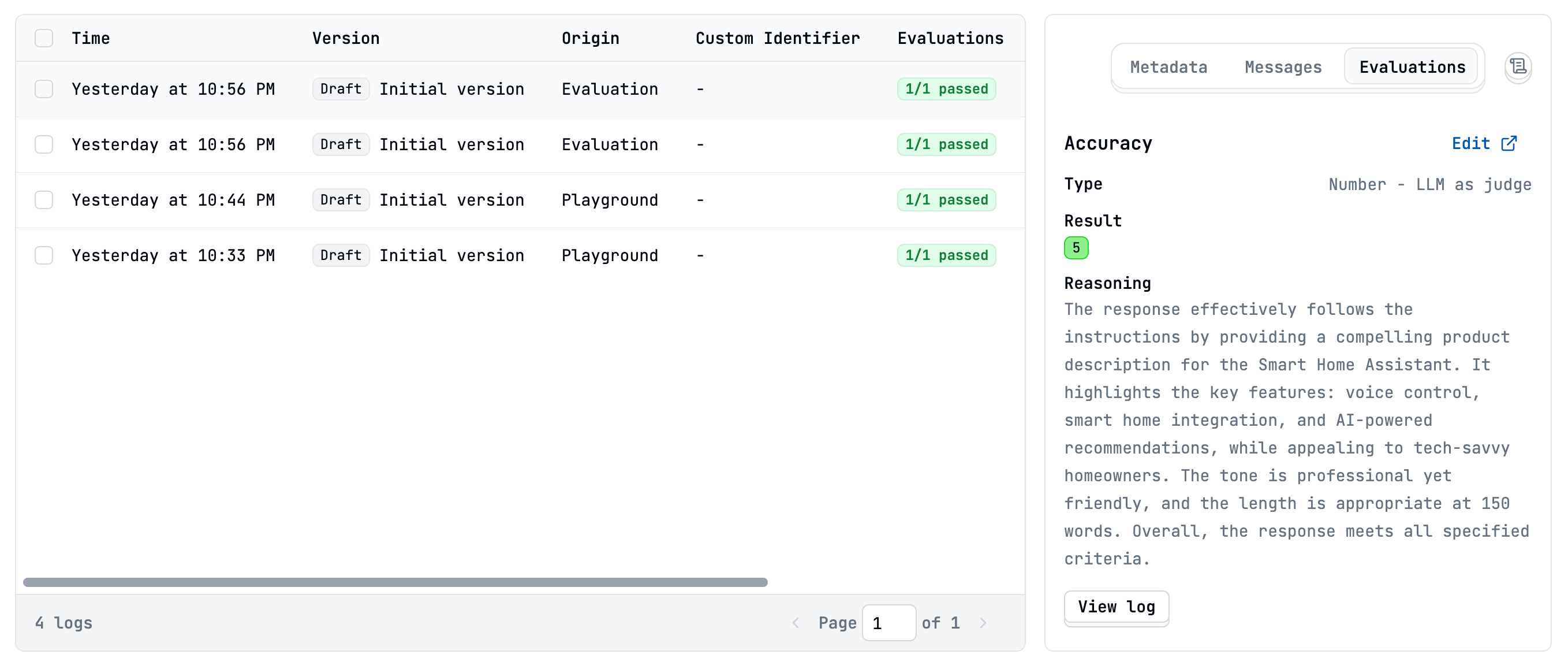
- Evaluations Tab (Per Prompt): View aggregated statistics, score distributions, success rates, and time-series trends for each specific evaluation.
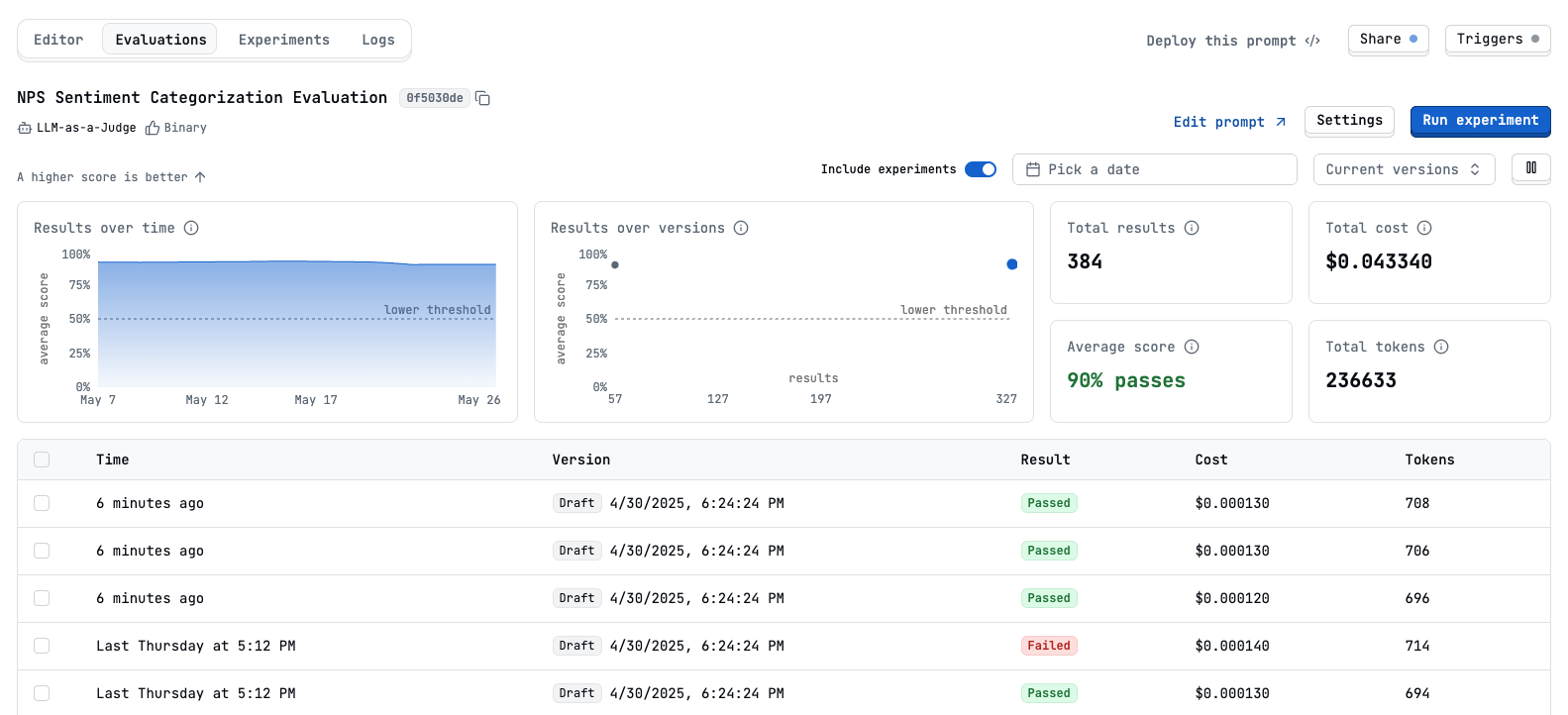
- Experiments: When you run evaluations as experiments, you can view detailed results, compare different variants
Next Steps
- Learn how to prepare data using Datasets
- Understand how evaluation results power Prompt Suggestions
- Explore the different Evaluation Types